Mastering Systematic Prompting: A Developer's Q&A on Key Techniques
Explore five systematic prompting techniques for LLMs: role-specific, negative constraints, JSON output, ARQ, and verbalized sampling. Q&A format explains each method's mechanism, impact, and practical setup.
In production systems, LLM reliability is non-negotiable. While many developers treat prompting casually, research has formalized it into precise techniques that address specific failure modes—structure, reasoning, or style. This Q&A covers five powerful methods that operate at the prompt layer without requiring model changes: role-specific prompting, negative constraints, structured JSON outputs, Attentive Reasoning Queries (ARQ), and multi-hypothesis verbalized sampling. Each technique is explained with practical insights, and we also walk through the minimal setup needed to test them using the OpenAI API.
1. Why is systematic prompting critical for LLMs in production?
When LLMs move from experimental to production environments, consistency becomes a top priority. A prompt that usually works is not enough—engineers need outputs that are reliable across every call. Traditional trial-and-error prompting leads to unpredictable behavior, especially when tasks involve complex reasoning, strict formatting, or domain-specific knowledge. Systematic prompting formalizes the process by isolating specific failure modes and applying targeted techniques. For example, role-specific prompting ensures the model stays within a professional persona, while negative constraints explicitly forbid unwanted patterns. This shift from ad-hoc iteration to structured engineering drastically improves output quality and reduces debugging time, making it essential for any production-grade LLM integration.
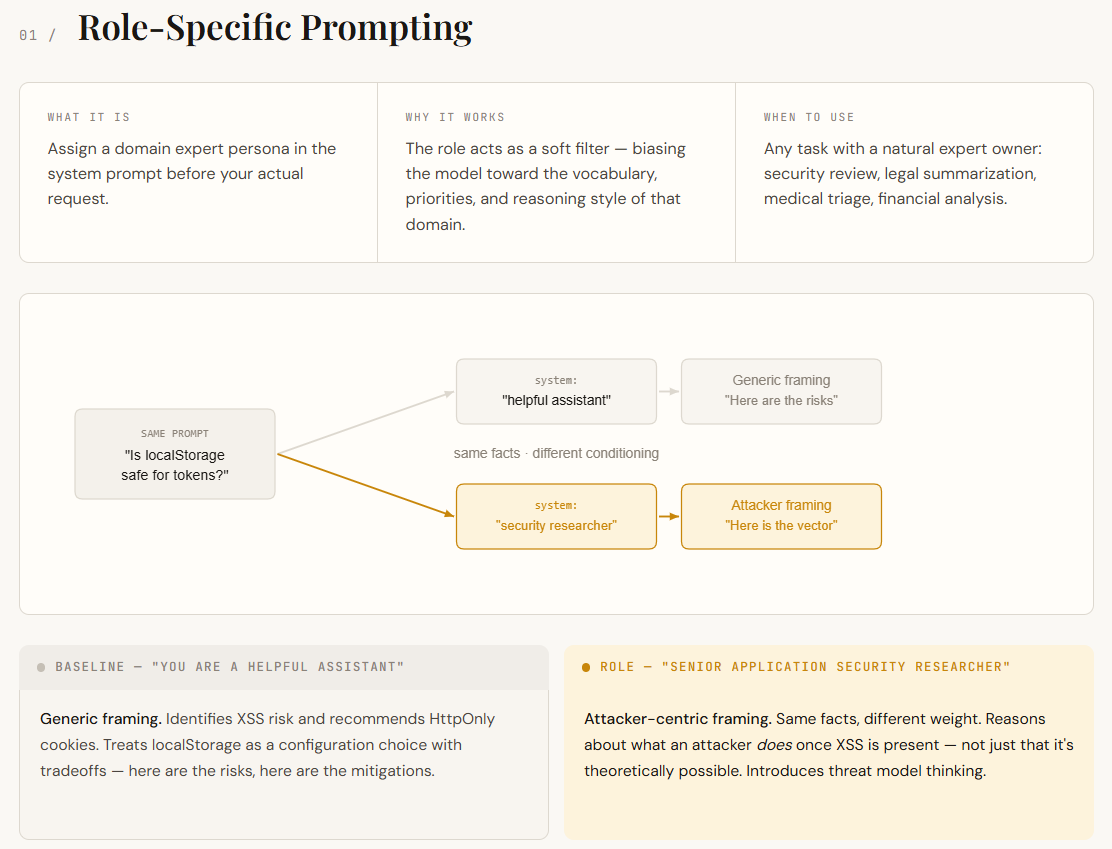
2. How does role-specific prompting improve output consistency?
Language models are trained on a vast mix of domains—legal, marketing, security, engineering, and more. Without a defined role, the model blends these voices, resulting in generic or inconsistent answers. Role-specific prompting assigns a clear persona in the system prompt, such as "You are a senior app developer" or "You are a legal expert." This steers the model toward the relevant knowledge and communication style. In practice, it leads to more precise and contextually appropriate responses. For example, asking the same technical question to a "senior developer" persona yields code-focused, practical advice, while a "project manager" persona might emphasize timelines and risks. The mechanism is simple: by narrowing the output space, the model reduces irrelevant associations and improves reliability without any fine-tuning.
3. What is negative prompting and how does it work?
Negative prompting, also called negative constraints, explicitly tells the model what to avoid in its output. Instead of only describing what you want, you add instructions like "Do not include any code snippets" or "Avoid marketing jargon." This technique is particularly useful for suppressing common failure modes, such as hallucinations or off-topic tangents. The model's attention mechanism naturally picks up on these restrictions, especially when they are placed near the end of the prompt. For example, when asking for a summary of a technical article, adding "Do not mention specific company names" can prevent the model from fabricating examples. Negative prompting works best when combined with positive instructions—it acts as a filter that removes unwanted patterns while still allowing creative flexibility.
4. How does JSON prompting enforce structured outputs?
Many applications require LLM outputs to be parsed as structured data, such as JSON. JSON prompting involves providing the model with a schema or example of the desired JSON structure, often with explicit instructions to output valid JSON. This can be done in the system prompt or as part of the user query. For instance, you might specify: "Return a JSON object with keys 'name', 'age', and 'occupation'." Advanced versions include providing a JSON schema or even few-shot examples. The model learns to format its response accordingly, though occasional formatting errors still occur. To improve reliability, you can ask the model to wrap the JSON inside a code block or use a specific marker. JSON prompting is essential for integrating LLM outputs into automated pipelines, databases, or APIs.
5. What are Attentive Reasoning Queries (ARQ)?
Attentive Reasoning Queries (ARQ) are a technique that forces the model to distribute its attention across multiple reasoning paths before converging on an answer. Unlike standard chain-of-thought, which follows a single linear sequence, ARQ explicitly asks the model to generate several hypotheses or viewpoints, then evaluate and combine them. For example, you might prompt: "First, list three possible explanations for the observed data. Then, for each explanation, list supporting and contradicting evidence. Finally, select the most plausible explanation." This reduces the risk of confirmation bias and surface-level reasoning. ARQ is especially valuable for complex analysis tasks where a single line of thought might miss critical alternatives. It works by expanding the model's focus and then synthesizing a more robust conclusion.
6. How does multi-hypothesis verbalized sampling work?
Multi-hypothesis verbalized sampling is a method where the model explicitly generates multiple candidate answers or hypotheses in its output, then selects or ranks them. It is similar to ARQ but often used for tasks with multiple valid outputs, such as creative writing or decision making. The prompt might say: "Propose three distinct strategies for solving this problem. For each, list its pros and cons. Then recommend the best one." This verbalizes the internal sampling process, making the model's reasoning more transparent and allowing fine-grained control over diversity. Compared to simply sampling multiple completions programmatically, verbalized sampling produces a single response that contains both the alternatives and the reasoning, which can be directly inspected. It is a lightweight way to incorporate ensemble-like thinking into a single API call.
7. What is the minimal setup needed to test these techniques?
To experiment with systematic prompting, you need three things: an OpenAI API key, a Python environment, and a simple chat wrapper. The standard approach is to securely load the API key at runtime using getpass, initialize the OpenAI client, and define a function like chat(system, user) that sends messages to the model (e.g., gpt-4o-mini). For side-by-side comparisons, you can add helper functions for formatting output sections and dividers. This keeps the code clean and reusable. You do not need any special libraries beyond openai and Python's standard library. With this setup, you can quickly test different system prompts, user instructions, and parameter variations to see how each technique affects output. The code is available in the original article, but the key is to keep the experiment loop isolated and focused only on prompt changes.